io_uring
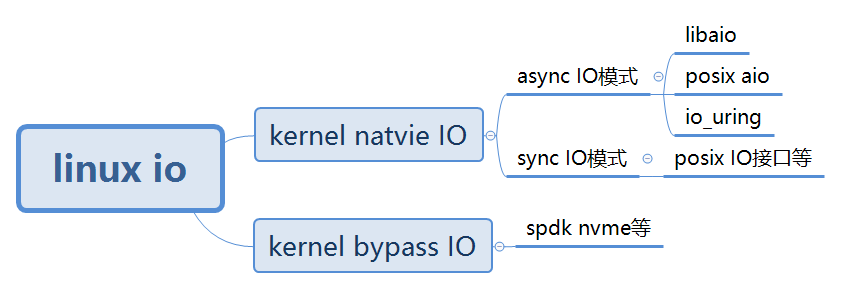

io_uring 是 kernel natvie aio 的一种,它是 Linux Kernel 5.1 版本加入一个特性。通过设计 io_uring 这套全新的 aysnc IO 系统调用接口,让应用程序可以获得更高的性能,更好的兼容性。
2.1 libaio 的局限
在 io_uring 出现之前,主流的使用 kernel aio 模式的接口是使用 libaio 接口,这种接口存在着如下一些局限:
(1) 仅支持 direct IO。在采用 aysnc IO 的时候,只能使用 O_DIRECT,不能借助文件系统缓存来缓存当前的 IO 请求,还存在 size 对齐(直接操作磁盘,所有写入内存块数量必须是文件系统块大小的倍数,而且要与内存页大小对齐)等限制,这直接影响了 aio 在很多场景的使用。
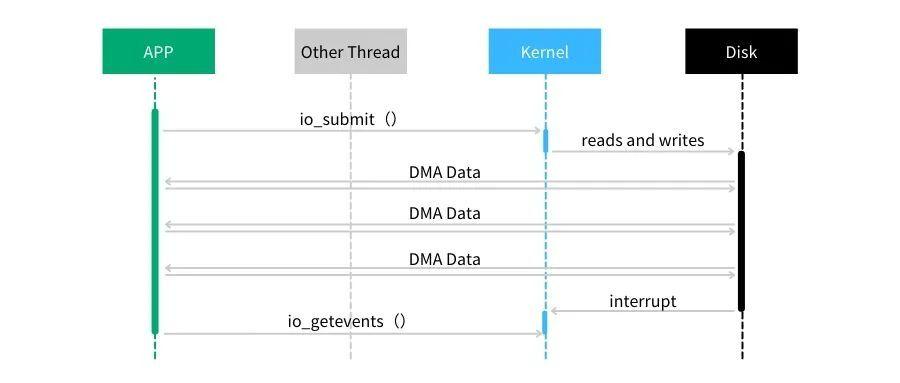
图2.1
例如:从图 2.1 的流程看,例如 read 请求来说,direct IO 的模式会把从盘上读取的数据直接返回给了用户态的内存空间,不会在 kernel 中缓存,当存在多次重复读取的场景,每次都需要读盘,大大增加了 kernel 的负担。
(2) 仍然可能被阻塞。即使应用层主观上,希望系统层采用异步 IO,但是客观上,有时候还是可能会被阻塞。
(3) 拷贝开销大。每个 IO 提交需要拷贝 64+8 字节,每个 IO 完成需要拷贝 32 字节,总共 104 字节的拷贝。这个拷贝开销是否可以承受,和单次 IO 大小有关:如果需要发送的 IO 本身就很大,相较之下,这点消耗可以忽略,而在大量小 IO 的场景下,这样的拷贝影响比较大。
(4) API 不友好。每一个 IO 至少需要两次系统调用才能完成(submit 和 wait-for-completion),需要非常小心地使用完成事件以避免丢事件。
io_uring 有如此出众的性能,主要来源于以下几个方面:
- 用户态和内核态共享提交队列(submission queue)和完成队列(completion queue),避免了数据在用户空间和内核空间的内存拷贝
- IO 提交和收割可以 offload 给 Kernel,且提交和完成不需要经过系统调用(system call)
- 支持 Block 层的 Polling 模式
- 通过提前注册用户态内存地址,减少地址映射的开销
- 队列采用了无锁的访问模式,通过内存屏障减少了竞争;
在共享的 ring buffer 设计中,针对提交队列(SQ),应用是 IO 提交的生产者(producer),内核是消费者(consumer);反过来,针对完成队列(CQ),内核是完成事件的生产者,应用是消费者。
不仅如此,io_uring 还可以完美支持 buffered IO,而 libaio 对于 buffered IO 的支持则一直是被诟病的地方(只支持directed IO)。
io_uring 提供了一套新的系统调用,应用程序可以使用两个队列,Submission Queue(SQ) 和 Completion Queue(CQ) 来和 Kernel 进行通信。这种方式类似 RDMA 或者 NVMe 的方式,可以高效处理 IO。
syscall
425 io_uring_setup
426 io_uring_enter
427 io_uring_register
io_uring 准备阶段
io_uring_setup 需要两个参数,entries 和 io_uring_params。
其中 entries,代表 queue depth。
io_uring_params 的定义如下。
struct io_uring_params {
__u32 sq_entries;
__u32 cq_entries;
__u32 flags;
__u32 sq_thread_cpu;
__u32 sq_thread_idle;
__u32 resv[5];
struct io_sqring_offsets sq_off;
struct io_cqring_offsets cq_off;
};
struct io_sqring_offsets {
__u32 head;
__u32 tail;
__u32 ring_mask;
__u32 ring_entries;
__u32 flags;
__u32 dropped;
__u32 array;
__u32 resv1;
__u64 resv2;
};
struct io_cqring_offsets {
__u32 head;
__u32 tail;
__u32 ring_mask;
__u32 ring_entries;
__u32 overflow;
__u32 cqes;
__u64 resv[2];
};
其中,flags、sq_thread_cpu、sq_thread_idle 属于输入参数,用于定义 io_uring 在内核中的行为。其他参数属于输出参数,由内核负责设置。
在 io_setup 返回的时候,内核已经初始化好了 SQ 和 CQ,此外,还有内核还提供了一个 Submission Queue Entries(SQEs)数组。
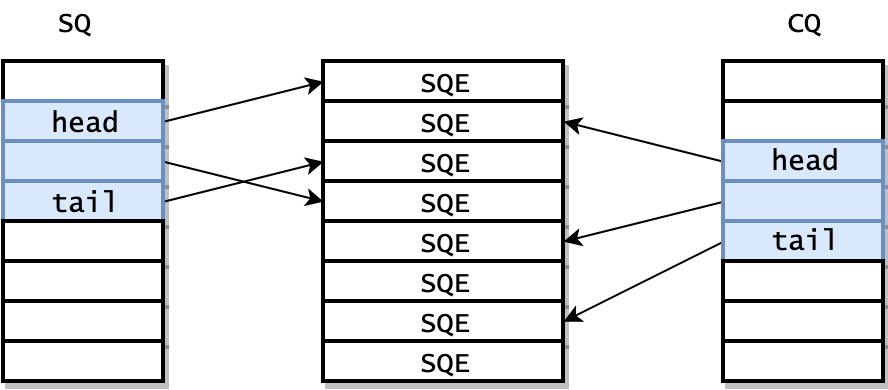
之所以额外采用了一个数组保存 SQEs,是为了方便通过 RingBuffer 提交内存上不连续的请求。SQ 和 CQ 中每个节点保存的都是 SQEs 数组的偏移量,而不是实际的请求,实际的请求只保存在 SQEs 数组中。这样在提交请求时,就可以批量提交一组 SQEs 上不连续的请求。
但由于 SQ,CQ,SQEs 是在内核中分配的,所以用户态程序并不能直接访问。io_setup 的返回值是一个 fd,应用程序使用这个 fd 进行 mmap,和 kernel 共享一块内存。
这块内存共分为三个区域,分别是 SQ,CQ,SQEs。kernel 返回的 io_sqring_offset 和 io_cqring_offset 分别描述了 SQ 和 CQ 的指针在 mmap 中的 offset。而 SQEs 则直接对应了 mmap 中的 SQEs 区域。
mmap 的时候需要传入 MAP_POPULATE 参数,以防止内存被 page fault。
IO 提交
IO 提交的做法是找到一个空闲的 SQE,根据请求设置 SQE,并将这个 SQE 的索引放到 SQ 中。SQ 是一个典型的 RingBuffer,有 head,tail 两个成员,如果 head == tail,意味着队列为空。SQE 设置完成后,需要修改 SQ 的 tail,以表示向 RingBuffer 中插入一个请求。
当所有请求都加入 SQ 后,就可以使用 :
int io_uring_enter(unsigned int fd, u32 to_submit, u32 min_complete, u32 flags);
来提交 IO 请求。
io_uring_enter 被调用后会陷入到内核,内核将 SQ 中的请求提交给 Block 层。to_submit 表示一次提交多少个 IO。
如果 flags 设置了 IORING_ENTER_GETEVENTS,并且 min_complete > 0,那么这个系统调用会同时处理 IO 收割。这个系统调用会一直 block,直到 min_complete 个 IO 已经完成。
这个流程貌似和 libaio 没有什么区别,IO 提交的过程中依然会产生系统调用。
但 io_uring 的精髓在于,提供了 submission offload 模式,使得提交过程完全不需要进行系统调用。
如果在调用 io_uring_setup 时设置了 IORING_SETUP_SQPOLL 的 flag,内核会额外启动一个内核线程,我们称作 SQ 线程。这个内核线程可以运行在某个指定的 core 上(通过 sq_thread_cpu 配置)。这个内核线程会不停的 Poll SQ,除非在一段时间内没有 Poll 到任何请求(通过 sq_thread_idle 配置),才会被挂起。
当程序在用户态设置完 SQE,并通过修改 SQ 的 tail 完成一次插入时,如果此时 SQ 线程处于唤醒状态,那么可以立刻捕获到这次提交,这样就避免了用户程序调用 io_uring_enter 这个系统调用。如果 SQ 线程处于休眠状态,则需要通过调用 io_uring_enter,并使用 IORING_ENTER_SQ_WAKEUP 参数,来唤醒 SQ 线程。用户态可以通过 sqring 的 flags 变量获取 SQ 线程的状态。
在提交 IO 的时候,如果出现了没有空闲的 SEQ entry 来提交新的请求的时候,应用程序不知道什么时候有空闲的情况,只能不断重试。为解决这种场景的问题,可以在调用 io_uring_enter 的时候设置 IORING_ENTER_SQ_WAIT 标志位,当提交新请求的时候,它会等到至少有一个新的 SQ entry 能使用的时候才返回。
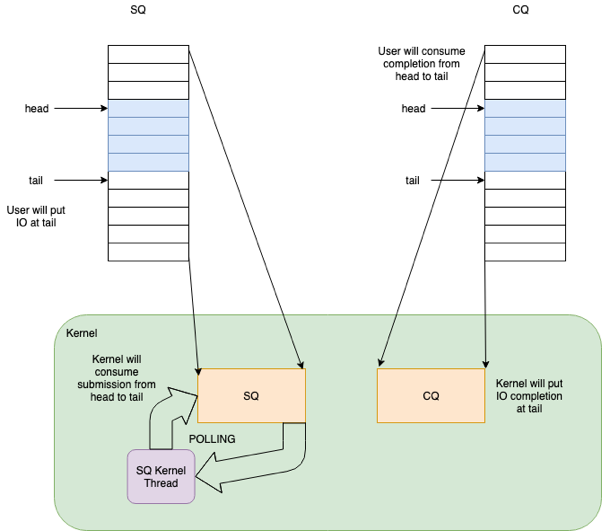
IO 收割
当 IO 完成时,内核负责将完成 IO 在 SQEs 中的 index 放到 CQ 中。由于 IO 在提交的时候可以顺便返回完成的 IO,所以收割 IO 不需要额外系统调用。这是跟 libaio 比较大的不同,省去了一次系统调用。
如果使用了 IORING_SETUP_SQPOLL 参数,IO 收割也不需要系统调用的参与。由于内核和用户态共享内存,所以收割的时候,用户态遍历 [cring->head, cring->tail) 区间,这是已经完成的 IO 队列,然后找到相应的 CQE 并进行处理,最后移动 head 指针到 tail,IO 收割就到此结束了。
由于提交和收割的时候需要访问共享内存的 head,tail 指针,所以需要使用 rmb/wmb 内存屏障操作确保时序。
所以在最理想的情况下,IO 提交和收割都不需要使用系统调用。
其它高级特性
io_uring 支持还支持以下特性。
IORING_REGISTER_FILES
这个的用途是避免每次 IO 对文件做 fget/fput 操作,当批量 IO 的时候,这组原子操作可以避免掉。
IORING_SETUP_IOPOLL
这个功能让内核采用 Polling 的模式收割 Block 层的请求。当没有使用 SQ 线程时,io_uring_enter 函数会主动的 Poll,以检查提交给 Block 层的请求是否已经完成,而不是挂起,并等待 Block 层完成后再被唤醒。使用 SQ 线程时也是同理。
IORING_REGISTER_BUFFERS
如果应用提交到内核的虚拟内存地址是固定的,那么可以提前完成虚拟地址到物理 pages 的映射,避免在 IO 路径上进行转换,从而优化性能。用法是,在 setup io_uring 之后,调用 io_uring_register,传递 IORING_REGISTER_BUFFERS 作为 opcode,参数是一个指向 iovec 的数组,表示这些地址需要 map 到内核。在做 IO 的时候,使用带 FIXED 版本的opcode(IORING_OP_READ_FIXED /IORING_OP_WRITE_FIXED)来操作 IO 即可。
内核在处理 IORING_REGISTER_BUFFERS 时,提前使用 get_user_pages 来获得 userspace 虚拟地址对应的物理 pages。在做 IO 的时候,如果提交的虚拟地址曾经被注册过,那么就免去了虚拟地址到 pages 的转换。
收割 IO 的轮询机制
在初始化实例时候通过设置 IORING_SETUP_IOPOLL 可以开启收割的轮询机制,这个功能让内核采用 Polling 的模式收割 Block 层的请求。
在轮询模式下,io_uring_enter 只负责把操作提交到内核的文件读写队列中。之后,用户需要多次调用 io_uring_enter 来轮询操作是否完成,通过主动轮询的模式,相对于等待中断信号的方式,可以提高收割的效率。
该种方式需要依靠打开文件的时候,设置为 O_DIRECT 的标记,该标记让应用程序调用 io_uring_enter 提交任务时,如下图所示的 io_read 直接调用内核的 Direct I/O 接口向设备队列提交任务。
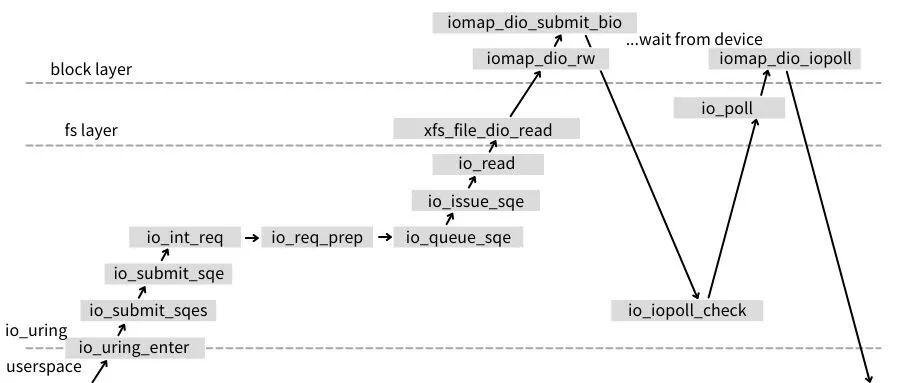
图3.4
从如上分析看,io_uring_enter 函数的功能主要是提交 IO、等待 IO 的完成或是同时执行两者功能,其具体的表现需要通过传入的参数来控制。
在 polling 模式下, 在设置了 IORING_ENTER_GETEVENTS 标志位,如果 min_complete 为非 0 的情况,那么 kernel 会只要有事件完成就会直接返回到应用;如果没有完成的事件,那么 kernel 会一直阻塞到有事件完成才会返回。
以上的执行过程都是在 IORING_SETUP_IOPOLL 模式执行的,如果是非 IORING_SETUP_IOPOLL 模式的情况下,没有设置 IORING_ENTER_GETEVENTS 标志位,应用程序只会检查 CQ ring 上是否有完成的事件,不会进入内核。设置了相应的标志位为 IORING_ENTER_GETEVENTS,那 kernel 会阻塞等到完成指定 min_complete 数量的事件才会返回。
3.2.3 轮询参数的配置
io_uring 大致可以分为默认、IOPOLL、SQPOLL、IOPOLL+SQPOLL 四种模式。可以根据操作是否需要轮询选择开启 IOPOLL。如果需要更高实时性、减少系统调用开销,可以考虑开启 SQPOLL。
只开启 IORING_SETUP_IOPOLL,会通过系统调用 io_uring_enter 提交任务和收割任务。
只开启 IORING_SETUP_SQPOL,无需任何系统调用即可提交、收割任务。内核线程在一段时间无操作后会休眠,可以通过 io_uring_enter 唤醒。
IORING_SETUP_IOPOLL 和 IORING_SETUP_SQPOLL 都开启,内核线程会同时对 io_uring 的队列和设备驱动队列做轮询。在这种情况下,用户态程序不需要调用 io_uring_enter 来触发内核的设备轮询了,只需要在用户态轮询完成事件队列即可。
3.3 buffer IO
每个 io_uring 都由一个轻量级的 io-wq 线程池支持,从而实现 Buffered I/O 的异步执行。对于 Buffered I/O 来说,文件的内容可能在 page cache 里,也可能需要从盘上读取。如果文件的内容已经在 page cache 中,这些内容可以直接在 io_uring_enter 的时候读取到,并在返回用户态时收割。否则,读写操作会在 workqueue 里执行。
如果没有在创建 io_uring 时指定 IORING_SETUP_IOPOLL 选项,io_uring 的操作就会放进 io-wq 中执行。
参考
- https://lore.kernel.org/linux-block/20190116175003.17880-1-axboe@kernel.dk/
- https://lwn.net/ml/linux-fsdevel/20190109160036.GK6310@bombadil.infradead.org/
- http://git.kernel.dk/cgit/fio/plain/t/io_uring.c
- https://lore.kernel.org/linux-block/20190211190049.7888-14-axboe@kernel.dk/
- https://lwn.net/Articles/743714/
- io_uring_setup.2\man - liburing - io_uring library
https://zhuanlan.zhihu.com/p/62682475