code snipaste
字符串拼接函数:strcat
使用strcat进行字符串拼接
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main() {
char *firstName = "Theo";
char *lastName = "Tsao";
char *name = (char *) malloc(strlen(firstName) + strlen(lastName));
strcpy(name, firstName);
strcat(name, lastName);
printf("%s\n", name);
return 0;
}
- 使用sprintf进行字符串拼接
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main() {
char *firstName = "Theo";
char *lastName = "Tsao";
char *name = (char *) malloc(strlen(firstName) + strlen(lastName));
sprintf(name, "%s%s", firstName, lastName);
printf("%s\n", name);
return 0;
}
字符串分割函数:strtok和strsep
strtok是C标准库函数,Linux内核代码里的函数均有自己的一份实现,但内核的strtok函数在2.6之后便被strsep替换。(Linux内核2.0.1版本的代码还有strtok)
strtok函数是用来分解字符串的,其原型是:
char *strtok(char str[], const char *delim);
其中str是要分解的字符串,delim是字符串中用来分解的字符,该函数返回分解后的字符串的起始位置指针。之所以是分解,就是说并没有生成新的字符串,只是在源字符串上面做了一些手脚,使得源字符串发生了变化
C 语言字符串分割可使用 strsep,是 strtok 函数的替代,而且可用于内核。
char *strsep(char **stringp, const char *delim);
函数接受的第一个参数是 in-out prarameter,在函数执行后会被更改,总指向当前要被分割的字符串;第二个参数顾名思义,是分割符。函数返回分割后的第一个字符串。函数执行的过程,是在 *stringp 中查找分割符,并将其替换为\0,返回分割出的第一个字符串指针(NULL 表示到达字符串尾),并更新 *stringp 指向下一个字符串。
#include <linux/string.h> // 或 string.h
#include <stdlib.h>
#include <stdio.h>
int main(int argc, const char *argv[]) {
char* const delim = "/";
char str[] = "some/split/string";
char *token, *cur = str;
while (token = strsep(&cur, delim)) {
printf("%s\n", token);
}
return 0;
}
注意:“char str[]”不能用“char *str”代替,前者填充为数组,后者指向常量不可更改,而 strsep 函数需要更改目标字符串。如果不了解 strsep 的执行过程,很容易用错。
strsep分割\r\n时,需要连一起作分隔符:
p = strsep(&tmp,"\r\n");
while(p){
p = strsep(&tmp,"\r\n");
}
而不能分开:
p = strsep(&tmp,"\r");
while(p)
{
p = strsep(&tmp,"\r");
}
p = strsep(&tmp,"\n");
while(p)
{
p = strsep(&tmp,"\n");
}
strtok 对比 strsep
#include <stdio.h>
#include <string.h>
#define DEVICEPARASTATIC_PATH "/etc/deviceParaStatic.conf"
#define DEVICEPARASTATIC_PATH_TEST "./deviceParaStatic.conf"
int get_profile_str_new_strtok(char *keyname, char *str_return, int size, char *path)
{
FILE *fp;
char *str_key = NULL;
char stream[128] = {0};
int totalLength = 0;
char *p = NULL;
fp = fopen(path, "r");
if (fp == NULL)
{
fprintf(stderr, "Can't open %s\n", path);
return -1;
}
memset(str_return, 0, size);
fseek(fp, 0, SEEK_SET);
while (fgets(stream, 128, fp) != NULL)
{
str_key = strstr(stream, keyname);
if (str_key == NULL || str_key != stream)
{
memset(stream, 0, sizeof(stream));
continue;
}
p = strtok(stream, "\r");
while (p)
{
p = strtok(NULL, "\r");
}
p = strtok(stream, "\n");
while (p)
{
p = strtok(NULL, "\n");
}
totalLength = strlen(stream) - strlen(keyname);
if (size < totalLength + 1)
{ /*total length + '\0' should not less than buffer*/
fprintf(stderr, "Too small buffer to catch the %s frome get_profile_str_new\n", keyname);
fclose(fp);
return -1;
}
else if (totalLength < 0)
{ /*can't get a negative length string*/
fprintf(stderr, "No profile string can get\n");
fclose(fp);
return -1;
}
else
{
strncpy(str_return, stream + strlen(keyname), totalLength);
str_return[totalLength] = '\0';
fclose(fp);
return strlen(str_return);
}
}
fclose(fp);
fprintf(stderr, "File %s content %s is worng\n", path, keyname);
return -1;
} /* end get_profile_str */
int get_profile_str_new_strsep(char *keyname, char *str_return, int size, char *path)
{
FILE *fp;
char *str_key = NULL;
char stream[128] = {0};
int totalLength = 0;
char *p = NULL;
fp = fopen(path, "r");
if (fp == NULL)
{
fprintf(stderr, "Can't open %s\n", path);
return -1;
}
memset(str_return, 0, size);
fseek(fp, 0, SEEK_SET);
while (fgets(stream, 128, fp) != NULL)
{
str_key = strstr(stream, keyname);
if (str_key == NULL || str_key != stream)
{
memset(stream, 0, sizeof(stream));
continue;
}
char *tmp = stream;
p = strsep(&tmp, "\r\n");
while (p)
{
p = strsep(&tmp, "\r\n");
}
p = strsep(&tmp, "\r");
while (p)
{
p = strsep(&tmp, "\r");
}
p = strsep(&tmp, "\n");
while (p)
{
p = strsep(&tmp, "\n");
}
totalLength = strlen(stream) - strlen(keyname);
if (size < totalLength + 1)
{ /*total length + '\0' should not less than buffer*/
fprintf(stderr, "Too small buffer to catch the %s frome get_profile_str_new\n", keyname);
fclose(fp);
return -1;
}
else if (totalLength < 0)
{ /*can't get a negative length string*/
fprintf(stderr, "No profile string can get\n");
fclose(fp);
return -1;
}
else
{
strncpy(str_return, stream + strlen(keyname), totalLength);
str_return[totalLength] = '\0';
fclose(fp);
return strlen(str_return);
}
}
fclose(fp);
fprintf(stderr, "File %s content %s is worng\n", path, keyname);
return -1;
} /* end get_profile_str */
void get_modename(char *attrVal, int len)
{
char attrName[32] = {0};
// char attrVal[128] = {0};
int i = 0;
int ret = 0;
snprintf(attrName, sizeof(attrName), "%s=", "ModelName");
ret = get_profile_str_new_strtok(attrName, attrVal, len, DEVICEPARASTATIC_PATH_TEST);
printf("strtok: %s,%d\n", attrVal, ret);
ret = get_profile_str_new_strtok(attrName, attrVal, len, DEVICEPARASTATIC_PATH_TEST);
printf("strsep: %s,%d\n", attrVal, ret);
}
int main()
{
char attrVal[128] = {0};
get_modename(attrVal, sizeof(attrVal));
// char test[100] = "hello";
// sprintf(test, "%s world", test);
// printf("%s", test);
return 0;
}
Manufacturer=UNIONMAN
CustomerSWVersion=V01.00.1
CustomerHWVersion=V01.00
BatCode=Device ID 54321
ModelName=UNG430N-C
Category=HGW
option60Code=0000
option60Mode
option125Code=01020304
option125String=SHCTCIPTVDHCPAAA
version=V01.00.1
数组和指针在函数参数的区别
#include<stdio.h>
void foo(int a[])
{
int b[10];
printf("foo :%p %p\n",a,&a);
printf("foo :%p %p\n",b,&b);
}
int main(int argc, char* argv[])
{
int a[10];
printf("main:%p %p\n", a, &a);
foo(a);
return 0;
}
main:0x7fffb4ded680 0x7fffb4ded680
foo :0x7fffb4ded680 0x7fffb4ded628
foo :0x7fffb4ded630 0x7fffb4ded630
在main函数中,a是数组类型,a和&a的地址值是一样的 在foo函数中,a是一个指针,指向数组类型,由于指针本身是对象,所以在内存中有专门空间存放其值。由此,在foo函数中,a的地址是指针的地址,&a的地址则是数组的地址。
结构体初始化
typedef struct test {
char a;
int b;
const char *c;
}Test;
方法一:按照成员的声明顺序,顺序初始化
Test t1 = {'A', 1, "test"};
方法二:指定初始化,成员顺序可以不定,Linux 内核多采用此方式
Test t2 = {
.b = 1,
.a = 'A',
.c = "test",
};
方法三:指定初始化,成员顺序可以不定
Test t3 = {
c: "test",
b: 1,
a: 'A',
};
将结构体初始化为0的两种方法:
// 1
Test t4 = {0};
// 2
Test t4;
memset(&t4, 0, sizeof(Test));
结构体拷贝
浅拷贝:拷贝后结构体内的指针指向同一块区域,不会分配新的内存
- 通过memcpy进行复制
- 直接用=运算符复制,C语言中,结构体是一篇连续的内存空间,使用=赋值操作,底层用到的就是memcpy
浅拷贝:拷贝过程中是按字节复制的,对于指针型成员变量只复制指针本身,而不复制指针所指向的目标
浅拷贝在有指针的情况下,会导致对内存进行重复释放引发错误。
结构体对齐
typedef struct{
char a;
short b;
char c;
int d;
}B;
int main()
{
int len_2 = sizeof(B);
printf("%d %d %d", sizeof(short), sizeof(int), len_2);
return 0;
}
//output: 2 4 12
64位系统会进行 4字节对齐
strdup函数
字符串拷贝库函数,一般和free()函数成对出现。 等效于malloc + memcpy,所以需要free。
#include <string.h>
char * __strdup(const char *s)
{
size_t len = strlen(s) +1;
void *new = malloc(len);
if (new == NULL)
return NULL;
return (char *)memecpy(new,s,len);
}
使用rand获取随机数
在头文件 #include <stdlib.h> rand()函数产生0到RAND_MAX范围的随机数
a + rand() % b:产生一个a到(a+b-1)的随机数,b表示范围
因为rand() 的内部实现是用线性同余法做的,它不是真的随机数,只不过是因为其周期特别长,所以有一定的范围里可看成是随机的,
rand() 会返回一随机数值,范围在 0 至 RAND_MAX 间。
在调用此函数产生随机数前,必须先利用 srand()设置好随机数种子,如果未设随机数种子,rand()在调用时会自动设随机数种子为 1。
rand()产生的是假随机数字,每次执行时是相同的。若要不同,以不同的值来初始化它.初始化的函数就是 srand()。
一般用当前时间生成随机种子:
#include <stdlib.h>
#include <time.h>
srand( (unsigned)time(NULL) );
memset初始化为1
int val = 0;
memset(buf, val, sizeof(buf));
int val = 1;
memset(buf, val, sizeof(buf));
int val = -1;
memset(buf, val, sizeof(buf));
memset是按字节赋值的,取变量val的后8位二进制进行赋值。 0 ,二进制是(00000000 00000000 00000000 00000000),取后8位(00000000) 1 ,二进制是(00000000 00000000 00000000 00000001),取后8位(00000001) -1,负数在计算机中以补码存储,二进制是(11111111 11111111 11111111 11111111),取后8位(11111111)
总结:memset()只有在初始化-1,0时才会正确。初始化其它值可能结果与预期不符合。
Linux系统C语言计时
#include <stdio.h>
#include <sys/time.h>
#include <math.h>
#include <time.h>
void do_func(){
int k;
for(int i=0;i<1000;i++)
for(int j=0;j<1000;j++)
k=i+j;
}
//int gettimeofday(struct timeval *tv,struct timezone *tz);精度到微秒
long us_timer(){
struct timeval start,end;
gettimeofday(&start,NULL);
do_func();
gettimeofday(&end,NULL);
return (end.tv_sec-start.tv_sec)*10^6+end.tv_usec-start.tv_usec;
}
/*
int clock_gettime(clockid_t clk_id,struct timespec *tp);精确到纳秒
CLOCK_REALTIME:系统实时时间,随系统实时时间改变而改变,即从UTC1970-1-1 0:0:0开始计时,中间时刻如果系统时间被用户改成其他,则对应的时间相应改变
CLOCK_MONOTONIC:从系统启动这一刻起开始计时,不受系统时间被用户改变的影响
CLOCK_PROCESS_CPUTIME_ID:本进程到当前代码系统CPU花费的时间
CLOCK_THREAD_CPUTIME_ID:本线程到当前代码系统CPU花费的时间
*/
long ns_timer(){
struct timespec start,end;
clock_gettime(CLOCK_MONOTONIC,&start);
do_func();
clock_gettime(CLOCK_MONOTONIC,&end);
return (end.tv_sec-start.tv_sec)*10^9+end.tv_nsec-start.tv_nsec;
}
int main(){
printf("花费时间 : %ld 微秒(us)\n", us_timer());
printf("花费时间 : %ld 纳秒(ns)\n", ns_timer());
return 0;
}
运行结果
#time ./a.out
花费时间 : 2016 微秒(us)
花费时间 : 2563087 纳秒(ns)
real 0m0.005s
user 0m0.005s
sys 0m0.000s
字符串数组初始化
在C语言编程中,当我们声明一个字符串数组的时候,常常需要把它初始化为空字符(Null)。总结起来有以下三种方式:
(1) char str[10]="";
(2) char str[10]={'\0'} = {0};
(3) char str[10]; str[0]='\0';
\0和'0'是不一样的
char a[2] = {32}; 这是所有字符初始化为空格
char a[10] = {'0'}; 意思将第一个字符初始化为0,其他为空字符即\0
第(1)(2)种方式是将str数组的所有元素都初始化为'\0',而第(3)种方式是只将str数组的第一个元素初始化为'\0'。如果数组的size非常大,那么前两种方式将会造成很大的开销。所以,除非必要(即我们需要将str数组的所有元素都初始化为0的情况),我们都应该选用第(3)种方式来初始化字符串数组。
获取文件大小
一、获取文件系统属性,读取文件大小。
在C语言库函数中有stat函数,可以获取文件的基本信息,其中就有文件大小。
#include <sys/stat.h>
int file_size(char* filename)
{
struct stat statbuf;
int ret;
ret = stat(filename,&statbuf);//调用stat函数
if(ret != 0) return -1;//获取失败。
return statbuf.st_size;//返回文件大小。
}
二、通过C语言文件操作,获取文件大小。
以fopen打开的文件,通过fseek可以定位到文件尾,这时使用ftell函数,返回的文件指针偏移值,就是文件的实际大小。
#include <stdio.h>
int file_size(char* filename)
{
FILE *fp = fopen(filename, "rb");//打开文件。
int size;
if(fp == NULL) // 打开文件失败
return -1;
fseek(fp, 0, SEEK_END);//定位文件指针到文件尾。
size=ftell(fp);//获取文件指针偏移量,即文件大小。
fclose(fp);//关闭文件。
return size;
}
三、注意事项: 第一种方式为直接读取文件信息,无需打开文件,所以更高效。 实测耗时差异为微秒级,忽略不计
四、测试代码:
#include <stdio.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/time.h>
int file_size1(char *filename)
{
struct timeval start = {0};
struct timeval end = {0};
gettimeofday(&start, NULL);
struct stat statbuf;
int ret;
ret = stat(filename, &statbuf); //调用stat函数
if (ret != 0)
return -1; //获取失败。
gettimeofday(&end, NULL);
long times = (end.tv_sec - start.tv_sec) * 1000000 + (end.tv_usec - start.tv_usec);
printf("%s: %ld\n", __FUNCTION__, times);
return statbuf.st_size; //返回文件大小。
}
int file_size2(char *filename)
{
struct timeval start = {0};
struct timeval end = {0};
gettimeofday(&start, NULL);
FILE *fp = fopen(filename, "rb"); //打开文件。
int size;
if (fp == NULL) // 打开文件失败
return -1;
fseek(fp, 0, SEEK_END); //定位文件指针到文件尾。
size = ftell(fp); //获取文件指针偏移量,即文件大小。
fclose(fp); //关闭文件。
gettimeofday(&end, NULL);
long times = (end.tv_sec - start.tv_sec) * 1000000 + (end.tv_usec - start.tv_usec);
printf("%s: %ld\n", __FUNCTION__, times);
return size;
}
int main(int argc, char **argv)
{
char *path = argv[1];
int pid = fork();
if (pid == 0)
{
int a = file_size1(path);
}
else
{
int b = file_size2(path);
}
return 0;
}
vprinf使用 && 封装打印函数
#include <stdarg.h>
#include <stdio.h>
#include <string.h>
static int printf_flag = 0; /* 打印标记 */
void Printf(const char* format, ...)
{
if(printf_flag)
{
va_list marker;
va_start(marker, format);
vprintf(format, marker);
va_end(marker);
}
else
{
/* 打印标记未开启 */
}
}
int main(int argc, char* argv[])
{
if(argc > 1 && !strcmp(argv[1], "debug"))printf_flag=1;
Printf("%s %s\n", "hello", " world");
}
获取当前系统时间:localtime
#include <stdio.h>
#include <string.h>
#include <time.h>
int main()
{
char cur_time[32] = {0};
time_t time_tmp = 0;
struct tm *time_ptr;
time(&time_tmp);
time_ptr = localtime(&time_tmp);
sprintf(cur_time, "%d%d%d%d%d%d", 1900 + time_ptr->tm_year, 1 + time_ptr->tm_mon, time_ptr->tm_mday, time_ptr->tm_hour, time_ptr->tm_min, time_ptr->tm_sec);
printf("%s: %d", cur_time, strlen(cur_time));
return 0;
}
此外,time()函数: 在计算机中时间都是从(1970年01月01日 0:00:00)开始计算秒数的
- 首先定义 time_t 类型(本质上是长整型long)来存储从1970年到现在经过了多少秒
- 再通过函数time()来获取从1970年到现在经过了多少秒
- 为了便于阅读,采用函数将“过了多少秒”进行转化
C-文件读:fread
#include <stdio.h>
#include <string.h>
int main()
{
FILE *fp;
char c[] = "This is runoob";
char buffer[20];
/* 打开文件用于读写 */
fp = fopen("data", "a");
/* 读取并显示数据 */
fread(buffer, strlen(c) + 1, 1, fp);
printf("%s\n", buffer);
fclose(fp);
return 0;
}
根据联合体判断字节序
大端:低位字节存放在高位地址
小端:低位字节存放在低位地址
#include <stdio.h>
typedef union
{
unsigned long bits32;
unsigned char bytes[4];
} TheValue;
int main()
{
TheValue theValue;
int isLittleEndian = 0;
theValue.bytes[0] = 1;
theValue.bytes[1] = 0;
theValue.bytes[2] = 0;
theValue.bytes[3] = 0;
isLittleEndian = (theValue.bits32 == 256);
printf("%u", theValue.bits32);
return 0;
}
数据的(字节序)大小端转换
#include <stdio.h>
#include <stdlib.h>
/* 数据的大小端转换 */
#define um_data_byte_swap(in, out) \
do { \
out = ((in & 0x000000ff) << 24) | ((in & 0x0000ff00) << 8) | ((in & 0x00ff0000) >> 8) | ((in & 0xff000000) >> 24); \
} while(0)
int main()
{
int a = 0x11223344;
int b = 0x0;
um_data_byte_swap(a, b);
printf("%x", b);
system("echo [cjf] hello");
return 0;
}
大小端存储转换
typedef union {
uint32_t word;
uint8_t bytes[4];
}word_msg_t;
uint32_t read_word_big_endian(void) {
word_msg_t tmp;
tmp.bytes[0] = read_byte();
tmp.bytes[1] = read_byte();
tmp.bytes[2] = read_byte();
tmp.bytes[3] = read_byte();
return (tmp.word);
}
&&、||运算符特点
#include <stdio.h>
int main() {
int i, j;
i = j = -1;
// int a = (++i && ++j) || i++;
int a = !(++i && j++) || i++;
printf("%d\t%d\t%d\n", i, j, a);//0 -1 1
return 0;
}
宏替换的特点
#include <stdio.h>
#define max(a,b) (a) > (b) ? (a) : (b)
int main()
{
int i = 10, j = 2;
int z = max(i++, j);
printf("%d,%d,%d", i, j, z);//12,2,11
return 0;
}
字符数组是右值,字符指针是左值
// had note
#include <stdio.h>
int main(){
char a[] = "abcd";
char *b = "ABCD";
a[0] = 'A';
// b[0] = 'a';
printf("%s\n", a);
printf("%s\n", b);
// a++; //不允许对a(右值)作自增,error: lvalue required as increment operand
b++;
printf("%s\n", a);
printf("%s\n", b);
return 0;
}
MAC地址合法性检查
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
int _mac_without_colons(char *src, char *dst)
{
char *p = src;
int i = 0, index = 0;
if (!src || !dst)
return -1;
if (strlen(src) != 17)
return -1;
for (i = 0; i < 17; i++)
{
if (p[i] != ':')
{
dst[index++] = p[i];
}
else
{
continue;
}
}
return 0;
}
int macCheck(char *mac)
{
int ret = -1;
int count = 0;
char *macTemp = NULL;
char macOne[3] = {0};
char macTwo[3] = {0};
char macThree[3] = {0};
char macFour[3] = {0};
char macFive[3] = {0};
char macSix[3] = {0};
if (mac == NULL)
{
return -1;
}
/* 检查是不是0-9、A-E */
ret = sscanf(mac, "%[0-9A-F]:%[0-9A-F]:%[0-9A-F]:%[0-9A-F]:%[0-9A-F]:%[0-9A-F]",
macOne, macTwo, macThree, macFour, macFive, macSix);
printf("%s %s %s %s %s %s\n", macOne, macTwo, macThree, macFour, macFive, macSix);
if (ret <= 0)
{
return -1;
}
/* 检查mac每个分段的长度 */
if ((2 != strlen(macOne)) || (2 != strlen(macTwo)) || (2 != strlen(macThree)) || (2 != strlen(macFour)) || (2 != strlen(macFive)) || (2 != strlen(macSix)))
{
return -1;
}
/* 检查“:”符号 */
macTemp = mac;
while (*macTemp != '\0')
{
if (*macTemp++ == ':')
{
count++;
}
}
if (count != 5)
{
return -1;
}
return 0;
}
int main()
{
char mac[] = "00:19:F0:FF:FD:36";
char new[13] = "0";
_mac_without_colons(mac, new);
printf("origin: %s \ncheckresult: %s \nnewMac: %s\n", mac, macCheck(mac) == 0 ? "yes" : "no", new);
return 0;
}
strsep根据字符分割字符串
#include <linux/string.h> // 或 string.h
#include <stdlib.h>
#include <stdio.h>
int main(int argc, const char *argv[])
{
char *const delim = "/";
char str[] = "some/split/string\r\nabc";
char *token, *cur = str;
while (token = strsep(&cur, delim))
{
printf("%s\n", token);
}
return 0;
}
重复宏定义
先定义的会被后定义的覆盖
// had note
#include <stdio.h>
#define max(a, b) (a) > (b) ? (a) : (b)
// 先定义的会被后定义的覆盖
#define MULTI_UPGRADE_MEMORY_LEN 0 /*128M , 131072 bits is 16384 bytes*/
#define UM_MULTI_UPGRADE
#ifdef UM_MULTI_UPGRADE
/* 预估升级文件的最大大小为128MB:在hitmap中一个位代表一个1024KB的报文 */
#define MULTI_UPGRADE_MEMORY_LEN (128 * 1024 / 8)
#endif
int main()
{
int i = 10, j = 2;
int z = max(i++, j);
printf("%d,%d,%d\n", i, j, z);
printf("%d", MULTI_UPGRADE_MEMORY_LEN);
return 0;
}
文件读写
// will
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/stat.h>
#include <string.h>
#define ZX279127S 1
#define ZX279128S 0
typedef struct
{
char aes_en_key[16]; //证书解密的秘钥,密文存放 //0x0 //0 ~15
char chip_id[4]; // 空片标识 "128s" //0x10 //16 ~19
} boot_header_simple;
int get_cputype()
{
return 1;
}
int main()
{
boot_header_simple head = {0};
int fdin = open("uboot.bin", O_RDWR);
int iRet = lseek(fdin, 0, SEEK_SET);
if (0 > iRet)
{
printf("ERR: fail to lseek");
return -1;
}
if (read(fdin, &head, sizeof(boot_header_simple)) != sizeof(boot_header_simple))
{
printf("Read bootloader header failed");
return -1;
}
if (get_cputype() == ZX279127S)
memcpy(&head.chip_id, "127s", sizeof(head.chip_id));
else if (get_cputype() == ZX279128S)
memcpy(&head.chip_id, "128s", sizeof(head.chip_id));
iRet = lseek(fdin, 0, SEEK_SET);
if (0 > iRet)
{
printf("ERR: fail to lseek");
return -1;
}
write(fdin, &head, sizeof(boot_header_simple));
}
参数入栈情况
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
#include <fcntl.h>
void test2();
void test1(){
int a = 1;
printf("a %p\n", &a);
test2();
}
void test2(){
int b = 1;
printf("b %p\n", &b);
}
void test(int a, int b, char *aa, char *bb, char aaa,char bbb){
printf("%p %p %p %p %p %p\n", &a, &b, &aa, &bb, &aaa, &bbb);
}
int main(int argc, char *argv[]){
//确定栈增长方向
test1();
//确定参数入栈顺序
test(1,2,"沧浪水", "http://www.freecls.com",'a','b');
return 0;
}
strchr用法
#include <stdio.h>
#include <string.h>
int main(){
char a[] = "[fe80::5258:ec0f:a218:3b0b]:18080";
char *b = NULL;
int c = 0;
b = strchr(a, ']');
b = strchr(b, ':');
printf("%s\n", b+1);
sscanf( b+1, "%i", &c);
printf("%i\n", c);
return 0;
}
C语言中 %d 与 %i 的区别 和注意事项 在 printf 格式串中使用时,没有区别 在 scanf 格式串中使用时,有点区别,如下:
- 在scanf格式中,%d 只与十进制形式的整数相匹配。
- 而%i 则可以匹配八进制、十进制、十六进制表示的整数。·
- 例如: 如果输入的数字有前缀 0(018、025),%i将会把它当作八进制数来处理,如果有前缀0x (0x54),它将以十六进制来处理。 所以注意事项:
- 如果你是个新手,且习惯性在数字前放个零啥的,劝你使用%d。
解析URL
#include <stdio.h>
#include <string.h>
int parseTestURL(char* testURL, char* destIP, int len_ip, char* destPort, int len_port, char *filepath, int len_file)
{
printf("[func: %s]: URL is %s, len is %d\n", __FUNCTION__, testURL, strlen(testURL));
char *ptoken = NULL, *pstart = NULL;
int offset = 0;
if ( NULL == testURL || NULL == destIP || NULL == destPort || NULL == filepath )
return -1;
if ( NULL == ( ptoken = strstr(testURL, "://") ) )
return -1;
/* ignore the symbol '://' */
pstart = ptoken + 3;
/* cut url */
ptoken = strstr(pstart, "/");
if ( ptoken )
{
offset = strlen(pstart) - strlen(ptoken);
strncpy(filepath, ptoken + 1, len_file - 1);
pstart[offset] = '\0';
}
else
{
printf("%s:%d parse TestURL error.\n", __FUNCTION__, __LINE__);
return -1;
}
ptoken = strstr(pstart, ":");
if ( ptoken )
{
offset = strlen(pstart) - strlen(ptoken);
strncpy(destPort, ptoken + 1, len_port - 1);
pstart[offset] = '\0';
strncpy(destIP, pstart, len_ip - 1);
}
else
{
strncpy(destPort, "80", len_port - 1);
strncpy(destIP, pstart, len_ip - 1);
}
printf("[func: %s]: parse result is [%s]:[%s]/[%s]\n", __FUNCTION__, destIP, destPort, filepath);
return 0;
}
int main() {
char hostname[] = "http://58.248.23.61:8080/services/contractrate/contract/rate/";
char dst_ip[16] = {0};
char dst_port[8] = {0};
char dst_uri[128] = {0};
parseTestURL(hostname, dst_ip, sizeof(dst_ip), dst_port, sizeof(dst_port), dst_uri, sizeof(dst_uri));
return 0;
}
自增自减demo
#include <stdio.h>
#include <string.h>
int main() {
int i ,j;
i = j = -1;
int z = (i++ && j++) | ++i;
printf("%d\t%d\t%d\t", i, j, z);// 1 0 1
return 0;
}
URL特殊字符编码处理
#include <stdio.h>
#include <string.h>
int encodeURL(char *orginURL, char *resultURL, int resultSize)
{
int i = 0, j = 0;
int len = strlen(orginURL);
if (0 == len)
{
printf("ERROR: The URL is NULL.\n");
return 1;
}
for (i = 0; i <= len; i++)
{
char tmp = orginURL[i];
if (tmp == '%')
{
resultURL[j++] = '%';
resultURL[j++] = '2';
resultURL[j++] = '5';
}
else
{
resultURL[j] = orginURL[i];
j++;
}
}
return 0;
}
int main()
{
char a[256] = "http://192.168.1.1/telnet_on?usr=CMCCAdmin&pwd=aDm8H%MdA";
char b[256] = {0};
encodeURL(a, b, 256);
printf("%s\n", a);
printf("%s", b);
return 0;
}
内核态按行读取文件
note:新版本内核不允许在内核态读写文件
内核态下没有fgets函数,如果要按行读取文件,需要用户自己实现。
static char *read_line(char *buf, int buf_len, struct file *fp)
{
int ret;
int i = 0;
mm_segment_t fs;
fs=get_fs();
set_fs(KERNEL_DS);
ret = fp->f_op->read(fp, buf, buf_len, &(fp->f_pos));
set_fs(fs);
if (ret <= 0)
return NULL;
while(buf[i++] != '\n' && i < ret);
if(i < ret) {
fp->f_pos += i-ret;
}
if(i < buf_len) {
buf[i] = 0;
}
return buf;
}
四个十六进制数合并成一个十六进制数
char sDec[4] = {0x05,0xc5,0xb3,0xea};
低字节序的情况下. 并且 int 占用 32bit.
char sDec[4] = {0x05,0xc5,0xb3,0xea};
int val = 0;
char *pBuf = (char*)&val;
pBuf[0] = sDec[3];
pBuf[1] = sDec[2];
pBuf[2] = sDec[1];
pBuf[3] = sDec[0];
这时val==0x05c5b3ea;
如果是高字节序那就更简单了.
char sDec[4] = {0x05,0xc5,0xb3,0xea};
int val = *(int*)sDesc;
How to suppress “unused parameter” warnings in C
在C语言代码里看到了如下宏定义:
#define UNUSED(x) ((x)=(x))
void test(int a){
UNUSED(a);
}
- 有些编译器,在变量或者参数未使用时会发出警告
- 编译参数
--Werror视警告为错误,出现任何警告即放弃编译。
当两者一起出现时,未使用变量就会报错,所以使用该宏规避编译器警告。
但是,x有些特殊情况并不能用赋值运算符,所以,更好的写法是:
#define UNUSED(x) (void)(x)
抑制编译器警告:
In C++ I was able to put a /.../ comment around the parameters. But not in C of course, where it gives me the error error: parameter name omitted.
// C++ only
void some_func(int /*x*/)
Or
// C and C++
void some_func(int x)
{
(void)x;
}
其它等效方法:
- completely remove the variable :
void foo( int ) - out comment the variable :
void foo( int /* value */ ) - use that macro :
void foo( int value ){ UNUSED(value); }
do{...}while(0)的使用
声明复杂的宏
使用do{...}while(0)构造后的宏定义不会受到大括号、分号等的影响,总是会按你期望的方式调用运行。
#defne DOSOMETHING()\
foo1();\
foo2();
if(a>0)
DOSOMETHING();
//替换后就是
if(a>0)
foo1();
foo2();
使用大括号括起来可能有所改善,但要是if...else...又不行了
#defne DOSOMETHING()\
{\
foo1();\
foo2();\
}
if(a>0)
DOSOMETHING();
else
foo3();
//替换后就是
if(a>0) {
foo1();
foo2();
};
else
foo3();
使用do{}while(0)可以避免受大括号、分号等的影响
#defne DOSOMETHING()\
do{\
foo1();\
foo2();\
}while(0)
if(a>0)
DOSOMETHING();
else
foo3();
//替换后就是
if(a>0)
do{
foo1();
foo2();
}while(0);
else
foo3();
Linux和其它代码库里的宏都用do{}while(0)来包围执行逻辑,因为它能确保宏的行为总是相同的,而不管在调用代码中使用了多少分号和大括号。
替换goto代码
在一些函数中,我们在return语句之前可能需要做一些工作,比如释放在函数一开始由malloc函数申请的内存空间,使用goto总是一种简单的方法:
int foo()
{
somestruct* ptr = malloc(...);
dosomething...;
if(error)
{
goto END;
}
dosomething...;
if(error)
{
goto END;
}
dosomething...;
END:
free(ptr);
return 0;
}
但由于goto关键字可能会使代码不易读,因此许多人都不推荐使用它,那么我们可以使用do{...}while(0)来解决这一问题:
int foo()
{
somestruct* ptr = malloc(...);
do{
dosomething...;
if(error)
{
break;
}
dosomething...;
if(error)
{
break;
}
dosomething...;
}while(0);
free(ptr);
return 0;
}
这里,我们使用do{...}while(0)来包含函数的主要部分,同时使用break替换goto,代码的可读性增强了。
避免由宏引起的警告
由于内核不同体系结构的限制,我们可能需要多次使用空宏。在编译的时候,这些空宏会产生警告,为了避免这种警告,我们可以使用do{...}while(0)来定义空宏:
#define EMPTYMICRO do{}while(0)
这样在编译的时候就不会产生警告。
定义单一的函数块来完成复杂的操作
如果你有一个复杂的函数且你不想要创建新的函数,那么使用do{...}while(0),你可以将一些代码放在这里面并定义一些变量,这样你就不必担心do{...}while(0)外面的变量名是否与do{...}while(0)里面的变量名相同造成重复了。
#defne FUNC_01()\
do{\
int a;
foo1();\
}while(0)
#defne FUNC_02()\
do{\
char a;
foo1();\
}while(0)
十六进制字符串转数字
#include <stdio.h>
int main()
{
char tmp[] = "0x11050001";
int id = 0;
//sprintf(id, "%x", tmp);
sscanf(tmp, "%x", &id);
int new = id & 0x0000ffff;
printf("%x", new);
return 0;
}
禁止sprintf()警告 'directive writing between 1 and 11 bytes into a region of size 6 '
https://www.coder.work/article/7530838#google_vignette
char tag[16];
sprintf(tag, "Literal - %d", literal);
上述代码,在开启所有警告视为错误时,会编译报错:
error: ‘%d’ directive writing between 1 and 11 bytes into a region of size 6 [-Werror=format-overflow=]
sprintf(tag, "Literal - %d", literal); //snprintf(tag, 16, "Literal - %d", literal);
^~
apps/ziptest/test_literals_lzma.c:42:15: note: directive argument in the range [-2147483648, 255] sprintf(tag, "Literal - %d", literal); //snprintf(tag, 16, "Literal
- %d", literal);
^~~~~~~~~~~~~~
apps/ziptest/test_literals_lzma.c:42:2: note: ‘sprintf’ output between 12 and 22 bytes into a destination of size 16 sprintf(tag, "Literal - %d", literal); //snprintf(tag, 16, "Literal - %d", literal); ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
cc1: all warnings being treated as errors Makefile:370: recipe for target
原因:因为字符串数组是16个字节,前缀是10个字节,所以剩下5个字节来写literal的字符串表示形式。由于int可能是32位,因此最大范围是2147483647,负数范围是-2147483648(11个字符),编译器会警告您(因为它能够计算所有大小)
现在,由于您知道范围不能在0-255之外,因此只需减小literal的大小即可,例如,将其声明为unsigned short(short可以是字符串的6个字节长:-32768如注释中指出的chux),因此您有余地您的值(value)。
unsigned short literal = 123;
sprintf(tag, "Literal - %hu", literal);
(您可以使用unsigned char格式说明符,使用范围从0到255的%hhu)
或仅在打印时进行转换:
sprintf(tag, "Literal - %hu", (unsigned short)literal);
(%u可能也可以工作,但是取决于编译器的智能程度:它仅分析变量args的格式还是大小?)
现在我们知道了为什么会出现警告,我们不要忘记最明显的解决方案:让我们定义一个足够大的数组。
char tag[25]; // 21 would have been okay
应该做。将其剃得太近通常不是一个好主意,除非您的资源不足。
c语言编译错误:warning: suggest parentheses around assignment used as truth value
https://blog.csdn.net/smilefxx/article/details/85029062
warning: suggest parentheses around assignment used as truth value 警告:建议使用赋值周围的括号作为真值
DIR *imagedir = NULL;
struct dirent *dirinfo = NULL;
while(dirinfo = readdir(imagedir)) //出现此错误。
原因:在C语言中,非0即代表TRUE,反之为FALSE。上面的语句以dirinfo的值用于最后的判断。但是由于长期的编程实践告诉我们,人们经常在赋值 = 和 大小判断 == 的使用上出现手误,所以gcc编译器为此要求我们明确地告诉编译器它是 = 而不是 ==,是故意,而非手误。
修改方法: while((dirinfo = readdir(imagedir))) while((dirinfo = readdir(imagedir)) != NULL)
error: unknown type name 'loff_t'
The only APIs loff_t is to be used with are under _GNU_SOURCE. These functions are in fcntl.h, and it will #define loff_t off_t when _GNU_SOURCE is defined, so either -D_GNU_SOURCE or -Dloff_t=off_t would be a workaround
# 海思makefile这样加
HI_EXT_CFLAGS += -D_GNU_SOURCE
应用层通过ioctl判断nand flash坏块
#include <mtd/mtd-user.h>
int fd = -1;
loff_t offset = 0;
if ((fd = open(mtd_dev, O_SYNC | O_RDONLY)) < 0)
{
perror("open()");
return -1;
}
/*分区内跳坏块*/
int ret = 0;
ret = ioctl(fd, MEMGETBADBLOCK, &offset);
// printf("[UMTEST]offset = %08llx, ret = %d, errno=%d, %s\n", offset, ret, errno, strerror(errno));
if(ret > 0) {
Printf("\nSkipping mtdblock bad block at 0x%08llx\n", offset);
offset += g_block_size;
if (offset != lseek(fd, offset, SEEK_SET))
{
perror("lseek()");
goto err;
}
continue;
}
EXPORT_SYMBOL() 错误
最近使用EXPORT_SYMBOL() 导出函数到内核符号表时,出现如下面的错误:
warning: data definition has no type or storage class
warning: type defaults to 'int' in declaration of 'EXPORT_SYMBOL'
warning: parameter names (without types) in function declaration
经查找资料,原来自己犯了一个非常低级的错误:没有包含module.h头文件,在文件中包含该头文件即可解决该告警:
#include <linux/module.h>
写文件后的fflush和fsync
read/write/fsync与fread/fwrite/fflush的关系和区别:
- read/write/fsync:linux底层操作;内核调用,涉及到进程上下文的切换,即用户态到核心态的转换,这是个比较消耗性能的操作。
- fread/fwrite/fflush:c语言标准规定的io流操作,建立在read/write/fsync之上 在用户层, 又增加了一层缓冲机制,用于减少内核调用次数,但是增加了一次内存拷贝。
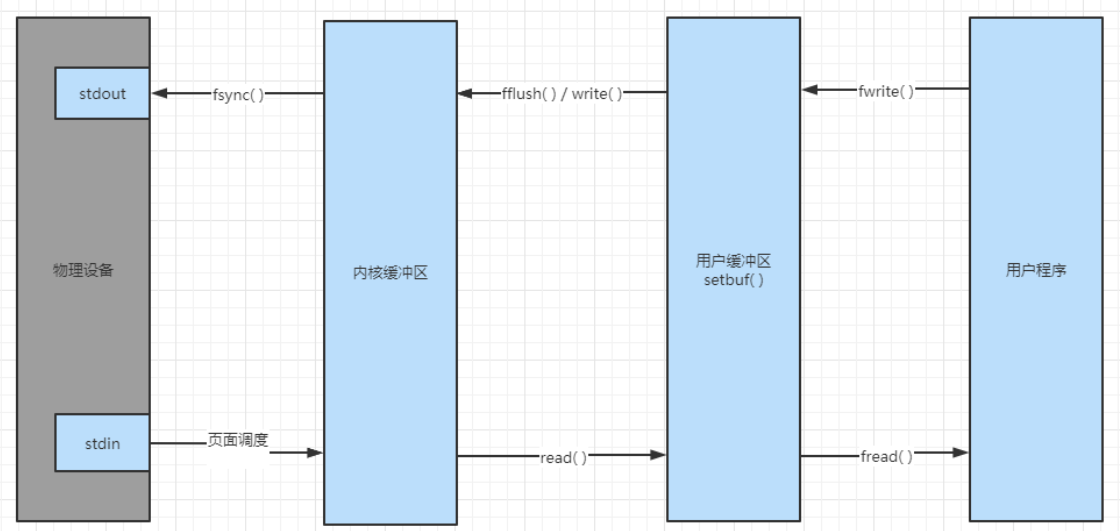
对于输入设备,调用fsync/fflush将清空相应的缓冲区,其内数据将被丢弃;
对于输出设备或磁盘文件,fflush只能保证数据到达内核缓冲区,并不能保证数据到达物理设备, 因此应该在调用fflush后,调用fsync(fileno(stream)),确保数据存入磁盘。
sync()、fflush()、fsync()这3个函数的区别:
用途不一样:
- sync,是同步整个系统的磁盘数据的.
- fsync是同步打开的一个文件到缓冲区数据到磁盘上.
- fflush是刷新打开的流的.
同步等级不一样:
- sync, 将缓冲区数据写回磁盘, 保持同步.(无参数)
- fsync, 将缓冲区的数据写到文件中.(有一个参数 int fd)
- fflush, 将文件流里未写出的数据立刻写出
FILE* fp;
fflush(fp);
fsync(fileno(fp));
fopen打开相对路径和绝对路径
https://zhuanlan.zhihu.com/p/603549501
char类型和signed char、unsigned char
https://gcc.gnu.org/bugzilla/show_bug.cgi?id=23087
char is a seperate type from signed char and unsigned char so they are always incompatiable when it comes to pointers to them.
gcc test.c -Wall -Werror
#include <stdio.h>
int main()
{
char *a = "a";
signed char *b = a;
unsigned char *c = a;
signed char *ps = "signed?";
unsigned char *pu = "unsigned?";
return 0;
}